
基于ChatGLM的部署实现
前言
ChatGLM-6B 是一个由清华大学KEG实验室和智谱AI基于GLM模型开发的人工智能助手。(参考链接:https://github.com/THUDM/ChatGLM-6B )

ChatGLM-6B 具有强大的语言处理能力,可以理解用户的问题和要求,并给出相应的答案和建议。
同时其作为ChatGPT轻量化的小参数版本,虽然效果上还有些差距,但其可以单卡部署在个人电脑上。
官方列出的硬件需求:
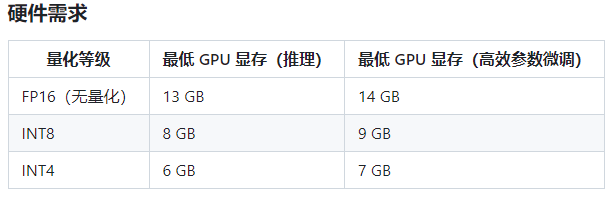
下面就是我记录的部署ChatGLM-6B的过程。
环境配置
- 通过git clone下载项目仓库
1
2
3git clone https://github.com/THUDM/ChatGLM-6B
cd ChatGLM-6B - 新建conda环境安装完激活环境
1
conda create -n chatglm python==3.8
1
conda activate chatglm
- 安装torch和cuda
这里参考pytorch官网:https://pytorch.org 注意torch的版本要高于1.10。
我选择使用的conda命令,对应版本如下1
conda install pytorch==1.10.1 torchvision==0.11.2 torchaudio==0.10.1 cudatoolkit=11.3 -c pytorch -c conda-forge
- 安装所需依赖
1
pip install -r requirements.txt
至此,基本环境配置完成。
准备模型文件
下载ChatGLM-6B模型文件,下载链接:https://huggingface.co/THUDM/chatglm-6b
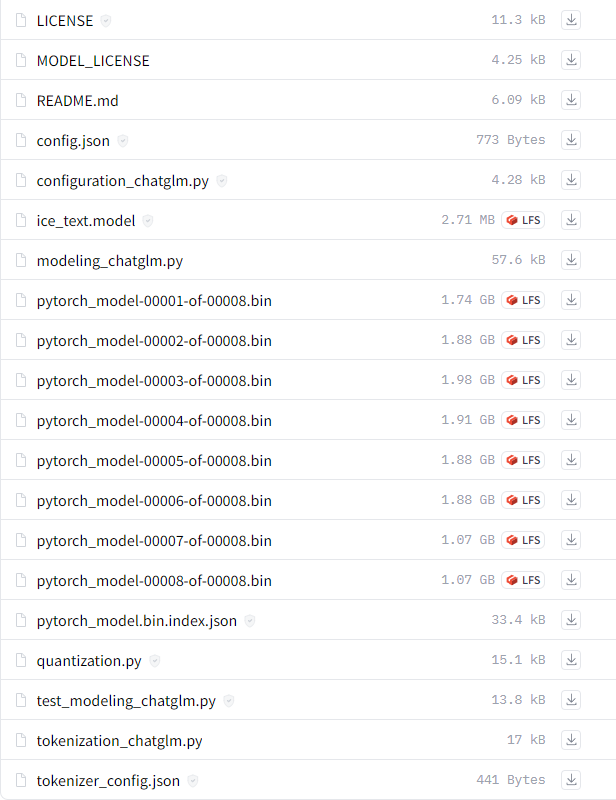
下载好的文件放在/THUDM/chatglm-6b路径下。当然可以修改成自己的路径,之后在执行代码的时候就需要将模型文件的路径修改成自己的。
代码运行demo
这个没有去尝试,copy自github
1 | >>> from transformers import AutoTokenizer, AutoModel |
命令行运行demo
运行仓库中 cli_demo.py文件
1 | python cli_demo.py |
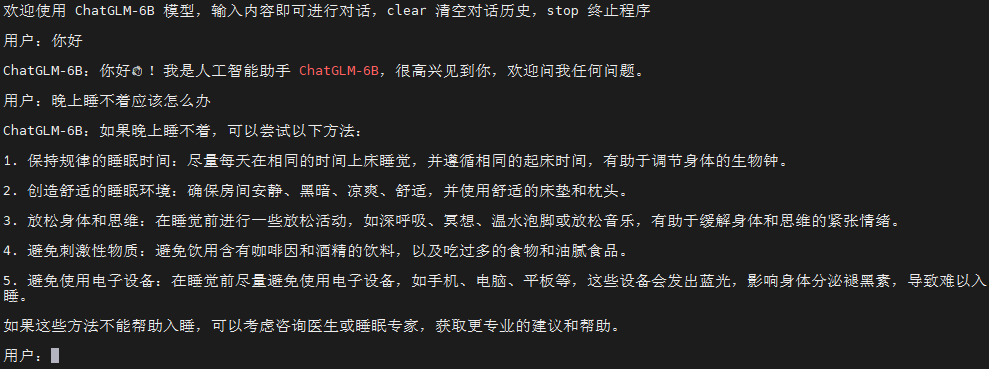
可以以命令行的形式进行交互。
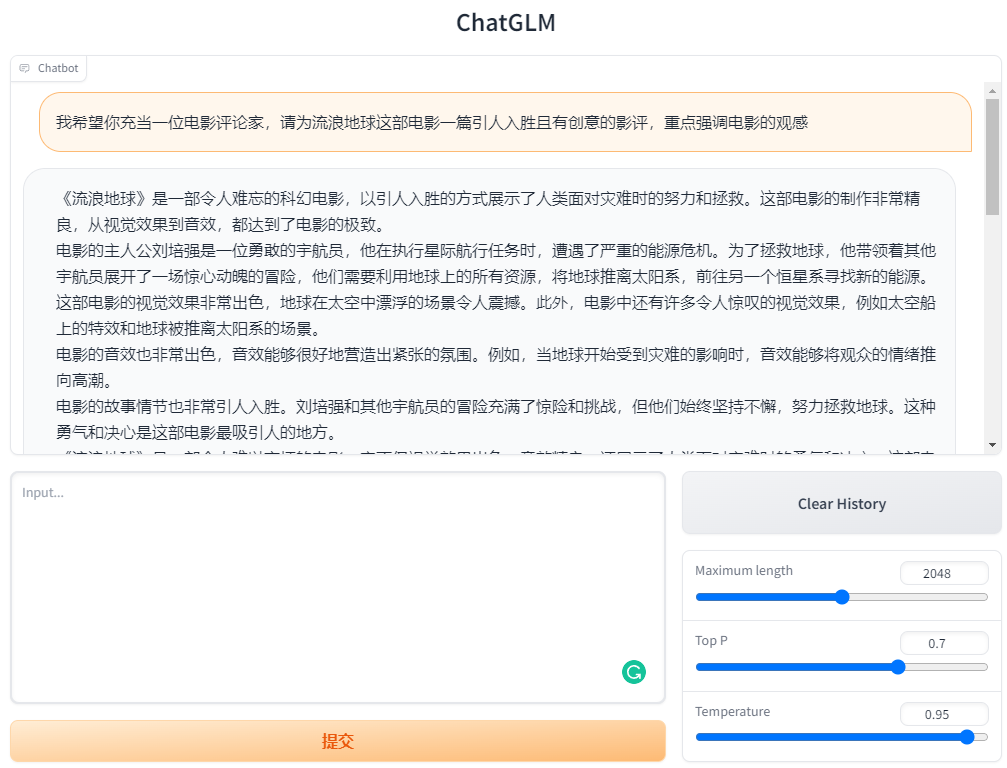
基于 Gradio 的网页运行demo
运行仓库中web_demo.py文件即可
1 | python web_demo.py |
基于 Streamlit 的网页运行Demo
先安装streamlit依赖
1 | pip install streamlit |
streamlit run web_demo2.py –server.port **** (可用端口号)
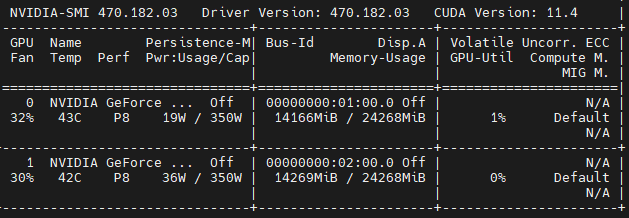
模型默认情况以 FP16 精度加载,大概需要 14GB 显存。
如果你的显存资源有限,可以考虑INT4/INT8轻量化,具体地:
1 | >>> model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().quantize(4).cuda() |
在这里加上.quantize(4)或者.quantize(8)即可。
总体过程大致就是这样。总体来说,ChatGLM不论是生成速度还是生成文本效果来说,都还是挺不错的。感兴趣的也可自己进行尝试。
后续还会有使用自己的数据来进行微调的过程,后续再回来补充~
- 标题: 基于ChatGLM的部署实现
- 作者: Leezh
- 创建于: 2023-06-16 10:51:57
- 更新于: 2023-06-21 10:37:13
- 链接: https://leegromit.top/2023/06/16/基于ChatGLM的部署实现/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。
评论